Introduction
Deep learning is a subset of machine learning, which has seen a tremendous growth in popularity recently. One of the reasons for that growth is that deep learning has brought huge advances to fields such as computer vision, speech recognition or machine translation. Those are fields that are mostly dealing with unstructured data that have traditionally been difficult for computers. Another reason for the success of deep learning, compared to traditional machine learning approaches, is its ability to automatically learn features from raw data, such as images, reducing the need for expensive manual feature engineering and making it applicable to a broader range of domains.
Deep learning is actually just a newer term for modern artificial neural networks. It’s called “Deep”, because these networks tend to be stacked in a sequence of several successive layers of computation. In a nutshell, common types of deep neural networks can learn to approximate very complex functions by being trained on (usually a lot of) known examples. After being trained, a deep learning model can be applied to previously unseen data and, with high probability, make correct predictions about that data.
Neural networks are not a new idea, they have been around for decades. What’s changed is research progress in how to train deep networks more effectively, the internet, resulting in much more available training data, and gaming, resulting in high performance GPUs that can do parallel numeric operations efficiently.
Neural networks work by a running the input data through series of consecutive computational layers. Each layer takes the output of its previous layer and applies some transformation to it (usually a mathematical operation), in turn providing its own output as input for the next layer, up to the final output. At their core, neural networks are based on linear algebra operations on numeric tensors (tensors being a generalization of vectors and matrices to n dimensions). That’s why we have to be able to represent data as a tensor in order to use it as input of a neural network.
Each layer produces an intermediate representation or encoding of the input data, i.e. pixel values of an image, that brings it closer to the desired output, i.e. a class describing the content of that image. What’s interesting, is that these representations are learned through exposure to known examples, rather than being explicitly programmed.
Some of the layered operations in neural network are parameterized and the parameters, or weights of these operations, sometimes millions for complex networks, are what’s learned in the training process. These weights contain the memory of a neural network, they represent how the network has learned mapping input to output as a result of searching for statistical structure in the example data.
The basic shape of a neural network, inputs and outputs, the flow of data through the layers as well as the operations involved is usually defined manually. We call this the neural network architecture, and it can look quite differently, depending on the kind of data we want to process, complexity constraints and other factors. More generally, we call all parameters that aren’t learned but defined manually, including the neural network architecture, hyperparameters, in order to distinguish them from the weights determined during training. There’s ongoing research to find good hyperparameters automatically for a given task but for now it’s still mostly a manual process.
Depending on the complexity of the neural network, the amount of training data, and the available hardware, training can take a long time, sometimes weeks or even months. Fortunately, training can often be done as an offline process. Running a trained model on new data for predictions, also called inference, is naturally much faster as it only requires one pass through the network, instead of several training runs.
I won’t go into explaining how neural networks work in more detail here because there’s already a lot of great material available on the subject. For a great visual explanation, I highly recommend you to watch the 3Blue1Brown Video series.
If you want to dive in deeper, I have added a few links to more learning resources at the end of this article. In the second part of this article series, I’m going to explain a few things in more detail to help you to follow through the examples.
We can also see neural networks as a new programming paradigm that allows us to learn certain functions. Inputs and outputs define the signature of our function. We define the neural network architecture to constrain the search space we want to use and we train the network on known examples to find a good implementation of the function. If we’re able to find a good solution, we can use the trained model as a black box just like any other function.
Deep learning is no silver bullet. It only works well with enough training data. Furthermore, while it works well for some tasks, it doesn’t for others. Despite some popular belief, deep learning does not enable general artificial intelligence. A more serious problem stems from the fact that training data created by humans such as language often contain racial and gender biases, which are picked up by a network, often reinforcing prejudices. Those are problems that have to be evaluated and addressed before choosing to use and how to use deep learning. Good programming language and API support can help to approach and master deep learning, which is what I will explore in the next section.
Why Scala?
The growing interest in deep learning has resulted in the development of many new neural network libraries in recent years. Python is undoubtedly leading as the language for implementing neural network algorithms, with many popular libraries and research implementations having their high-level parts written in Python. Lower level primitives such as the linear algebra operations underlying deep learning are usually written in C++ for performance and have almost always specialized GPU implementations as well. While Python is a great language, especially for scientific computing, data science and machine learning research, deep learning will probably become much more ubiquitous in software development and will be an essential part of many production systems in the future, systems written in a variety of languages often running on the JVM. Caused by that shift, we’ll also likely see more unified data science and software engineering teams similar to what’s happening in DevOps.
Moreover, as shown in this article, learning and inference is only a small part of machine learning systems. “… the majority of complexity manifests in data preparation, feature engineering, and operationalizing the distributed systems infrastructure necessary to perform these tasks at scale.” That last part is especially true for deep learning, as many neural networks tend to be computationally demanding and very data hungry, working best when fed with large numbers of training examples. That’s an area Scala is already good at, powering many of today’s large scale distributed and big data/fast data systems.
So why not go one step further and create, train and run neural networks using Scala as well? The language has as set of features that make it particularly well suited for building neural networks:
- Its functional nature and expressiveness is ideal for elegant composition of tensor operations and neural network architectures.
- Scala’s syntax and its type inference enables expressing tensor operations in a concise and readable way, similar to what you can do in dynamically typed languages like Python or R.
- At the same time, its powerful static type system can help catching certain kinds of errors early on at compile time, adding safety and often making development and especially maintenance more productive.
Last but not least, and that’s of course just my personal opinion, Scala is oftentimes fun to program in.
What I want to do in the remainder of this article is to explore what deep learning libraries are available for Scala today and what they have to offer. Before we look at specific libraries, let’s first discuss what we expect from a deep learning library.
What to expect from a deep learning library?
As we’ve seen in the introduction, neural networks are based on linear algebra operations on numeric tensors. That’s why efficient numeric computing is essential for running and especially for training neural network models. Nowadays that means support for running on GPUs, which are by magnitudes faster than CPUs for this kind of computation. It also essentially means Nvidia GPUs for the time being because, with some exceptions, most deep learning libraries rely on CUDA for GPU computations.
Therefore, a neural network library should provide an API for tensor operations that can be executed efficiently on specialized hardware like GPUs. Such an API should provide operations for creating and initializing tensors, reading/writing values from/to tensors, copying and transforming tensors. It should also provide core math operations such as tensor addition, matrix multiplication and so on. Combining those core building blocks in order to build higher-level functionality should be as easy as possible.
We could build a neural network from scratch using only these low level operations, and for research that level of control can sometimes be necessary. In most cases though, we would waste time and effort, trying to reinvent the wheel.
What we’re usually interested in is a higher level API that makes it easy to define a neural network architecture as well as train, evaluate and run a model. We would like that API to have “batteries included”, already providing building blocks for common tasks and ways to compose and extend them. For instance, most neural network APIs offer implementations of common layer types (i.e fully connected and convolutional layers) and activation functions as well as ways to parameterize and compose them in order to build a network architecture.
Training is usually the most complex part of a neural network. A library should therefore provide implementations of things like backpropagation (automatic computation of derivatives), optimization algorithms and loss functions. We also want it to take care of resource management and distribution, letting us focus on the training task itself.
An important part of the training process is the evaluation of model performance. Since training of more complex models is computationally expensive and can take days or even weeks, we want to get metrics as soon as possible, so evaluation should be integrated into the training loop. We also would like to define custom accuracy metrics and ideally get visualizations of those metrics out of the box.
Because a large part of a deep learning pipeline is made of data preparation, functionality for loading data, preprocessing and vectorization is just as important as the learning part itself. A library providing the right tools and integrations out of the box can make those tasks much easier.
Now that we have a rough idea what we expect from a neural network library, let’s define a list of criteria, that will help us to select matching libraries:
- Open source license.
- Callable from Scala. While a Scala API would be nice, Java counts as well.
- Supports creation and training of models, not only inference (loading trained models and doing predictions).
- High-level API that offers building blocks for creating common neural network architectures with little overhead i.e. common layer types, optimizers and helpers for training and evaluation of models.
- A certain level of maturity i.e. has documentation, examples and is actually working.
- Is being actively developed (i.e. has seen some commits within the last months).
- Supports running on CPUs as well as on compatible GPUs for better performance and allows training on multiple GPUs.
- Runs as standalone Scala program (i.e. not only as part of Spark).
- Bonus: Provides a “model zoo” of common neural networks (possibly already pre-trained on some dataset) and can import existing models created in other libraries for reuse.
Library selection
After a non exhaustive search based on the criteria above, I’ve chosen to have a closer look at the following libraries.
Note that the selection does not claim to be fully objective. Please feel free to contact me if you found another library that you think should be included as well.
Eclipse Deeplearning4j
![]() Deeplearning4j (DL4J) is a deep learning library for the JVM, primarily written in Java that became an Eclipse foundation project earlier this year. Compared to other more research oriented deep learning libraries, DL4J emphasises its focus on enterprise Java deployments and its integration with Big Data frameworks such as Hadoop and Spark.
Deeplearning4j (DL4J) is a deep learning library for the JVM, primarily written in Java that became an Eclipse foundation project earlier this year. Compared to other more research oriented deep learning libraries, DL4J emphasises its focus on enterprise Java deployments and its integration with Big Data frameworks such as Hadoop and Spark.
Under the hood, it uses ND4J (N-Dimensional Arrays for Java), a library for fast numeric computation and linear algebra operations on tensors written in Java and C++. ND4J works with float and double tensors and has GPU support based on CUDA. ND4S is a Scala wrapper on top of ND4J that uses Scala features such as operator overloading in order to offer a nicer syntax.
DL4J offers a high level Java API for creating, training and running neural networks that provides building blocks for most common neural network types. It’s easy to use from Scala, but lacks some of the features a native Scala API could offer.
DL4J also includes an ecosystem of supporting software such as DataVec for data preprocessing and vectorization, or the training UI for monitoring of the training process. DL4J can, with some restrictions import models created with Keras, a popular high-level Python deep learning library. It can scale vertically by supporting parallel training on multiple GPUs as well as horizontally through its Spark integration. Commercial support is available through Skymind, a company founded by the DL4J creators that employs many of the current DL4J developers. DL4J provides as model zoo containing mostly image classification models.
ScalNet
ScalNet is a Scala API on top of DL4J inspired by Keras. ScalNet aims to make prototyping neural networks with Scala faster by offering high level building blocks for creating and training neural network through a concise Scala API. Because it uses DL4J under the hood, it shares many of its properties and you can use, for instance, ND4S and DataVec from ScalNet as well. It is currently in alpha, and many things are still missing, so it might not completely meet our maturity criterion. Contrary to the information in the readme, there is no need to build the DL4J chain and ScalNet from source, as prebuilt binaries exist for Scala 2.10/2.11 for the current version 0.9.1. There is also a branch with Scala 2.12 support.
TensorFlow for Scala
![]() TensorFlow is a popular numeric computing library from Google with strong support for deep learning. The core is written in C++ and supports execution on GPUs via CUDA. Programming in core TensorFlow is usually done by first creating a dataflow graph or computational graph, a symbolic representation of the computations and their dependencies. It is a mere description of the computation without executing anything. You then create a session that executes the graph on the existing computational resources. Advantages of this separation are much better options for optimization and parallelization on multiple GPUs and machines as well as better decoupling of business logic and resource management. At a high level, this is conceptually similar to how Akka Streams separates defining streams from running them (actors being the “computational resources” here).
TensorFlow is a popular numeric computing library from Google with strong support for deep learning. The core is written in C++ and supports execution on GPUs via CUDA. Programming in core TensorFlow is usually done by first creating a dataflow graph or computational graph, a symbolic representation of the computations and their dependencies. It is a mere description of the computation without executing anything. You then create a session that executes the graph on the existing computational resources. Advantages of this separation are much better options for optimization and parallelization on multiple GPUs and machines as well as better decoupling of business logic and resource management. At a high level, this is conceptually similar to how Akka Streams separates defining streams from running them (actors being the “computational resources” here).
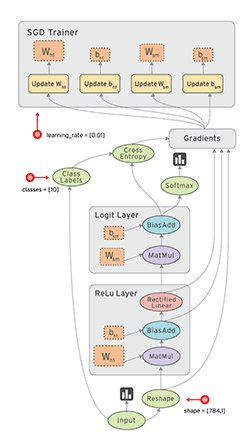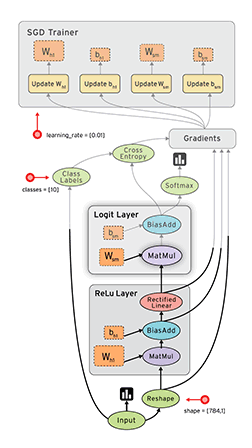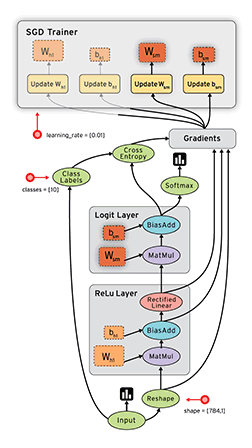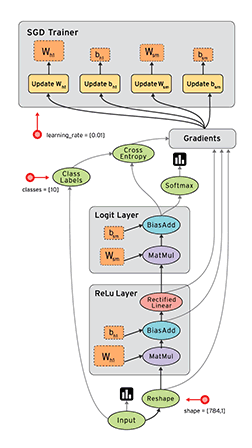 Support for eager execution was introduced recently as an experimental feature for running operations immediately in an imperative style instead of building a dataflow graph.
Support for eager execution was introduced recently as an experimental feature for running operations immediately in an imperative style instead of building a dataflow graph.
TensorFlow provides high level Python APIs for data preprocessing, creation and training of neural networks. Bindings for other languages like Java, Go and Rust are available but are primarily meant for inference (making predictions from trained models).
TensorFlow for Scala is a Scala API for TensorFlow created by Anthony Platanios. It is not an official TensorFlow module, but an independent project. It leverages the core TensorFlow C++ operations for high performance and GPU support. It provides a tensor API similar to NumPy for creating and manipulating tensors that also offers an imperative (eager execution) version of most TensorFlow core operations.
The core API is a Scala rewrite of a large part of the TensorFlow Python API that allows you to create and run a symbolic computation graph on tensors.
TensorFlow for Scala also adds its own high level learn API on top of the lower level APIs for building, running and training neural networks. It is similar to Keras (which is part of TensorFlow), but builds on Scala features to offer a rich and strongly typed functional API.
It is possible to load and reuse existing TensorFlow models as well as write them in the TensorFlow model serialization format, making it possible to leverage many available pretrained models. It is still a young project, but has made rapid progress last year.
MXNet
![]() MXNet is a deep learning library created in a joint effort from researchers of several universities. It recently moved under the Apache umbrella as an incubator project. MXNet is supported by companies such as Amazon, Intel and Baidu and is the Deep Learning Framework of Choice at AWS partly due to of its scalability. Similar to TensorFlow, its core is written in C++ with GPU support through CUDA.
MXNet is a deep learning library created in a joint effort from researchers of several universities. It recently moved under the Apache umbrella as an incubator project. MXNet is supported by companies such as Amazon, Intel and Baidu and is the Deep Learning Framework of Choice at AWS partly due to of its scalability. Similar to TensorFlow, its core is written in C++ with GPU support through CUDA.
MXNet offers APIs for a bunch of languages including Python, R, Julia, JavaScript, Scala and Go. In contrast to TensorFlow, the Scala API is an official part of the project. In MXNet, trained models can be serialized in a language agnostic way so it is possible to load and use a model from the Scala API that was created using Python.
Similar to TensorFlow, MXNet supports creating symbolic computation graphs, decoupling computation logic from execution. Furthermore, it provides support for eager execution as well for a more imperative approach. MXNet has recently introduced a high level machine learning API called gluon. As of now, gluon is only available for Python, though.
In the second part of this series, we’ll get our hands dirty, starting with a very simple example to see you how it looks like to create, train and run a neural network with each of the libraries presented here.
Learning Resources
Here are a few pointers for more material that might be helpful for further reading/learning.
Books
- For learning the theoretical foundations, there’s Deep Learning by Goodfellow et al.
- For a more hands on approach, Deep Learning with Python from Keras Author Francois Chollet is a very good resource aimed at developers.
- Neural Networks and Deep Learning is a free online book about deep learning with good visual explanations.
- Deep Learning: A Practitioner’s Approach explains deep learning concepts and uses DL4J to implement them.
Online Courses
- Practical Deep Learning For Coders. Free hands-on course by Jeremy Howard.
- Deep Learning Specialization by Andrew Ng at Coursera.
- Deep Learning Nanodegree at Udacity.