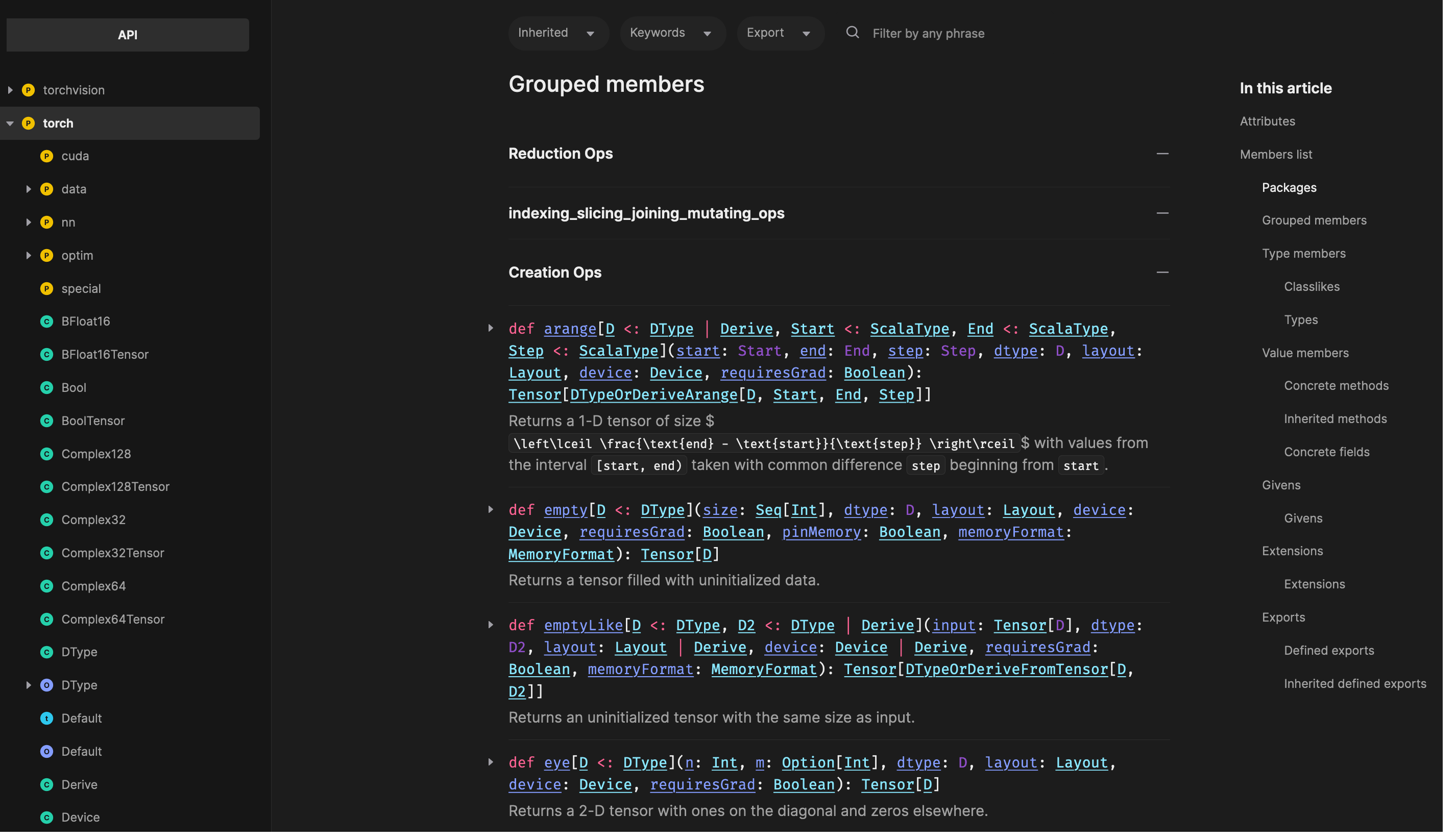
torch.Tensor(1)res3: Tensor[Int32] = tensor dtype=int32, shape=[], device=CPU 1


| App A |
|---|
| Business logic |
| UI |
| Persistence |
| Auth |
| … |
| App B |
|---|
| Business Logic |
| UI |
| Persistence |
| Auth |
| … |
| App C |
|---|
| Business Logic |
| UI |
| Persistence |
| Auth |
| … |
![]()
![]()

![]()
![]()
![]()
![]()


| App A |
|---|
| Business logic |
| UI |
| Persistence |
| Auth |
| … |
| App B |
|---|
| Business Logic |
| UI |
| Persistence |
| Auth |
| … |
| App C |
|---|
| Business Logic |
| UI |
| Persistence |
| Auth |
| … |
![]()
![]()
![]()
![]()
![]()
![]()
![]()





?
Cat
Dog
Cat


Tensors are homogeneous multidimensional rectangular arrays of numbers
Let’s learn the identity function!
model.weightsres20: Tensor[Float32] = tensor dtype=float32, shape=[1], device=CPU [0.1490]

val x = torch.Tensor(39)
val y = x // our "label" here is just the inputval z = model(x)z: Tensor[Float32] = tensor dtype=float32, shape=[1], device=CPU [5.8126]
Let’s see how far we’re off
val loss = (z - y).absloss: Tensor[Float32] = tensor dtype=float32, shape=[1], device=CPU [33.1874]

Can we change the weights to make the loss go down?

class Model:
val weights = torch.rand(Seq(1), requiresGrad=true)
def apply(x: Tensor[Int32]) = x * weights
val model = new Model()Let’s use the torch.nn API instead
import torch.nn
val model = nn.Linear(inFeatures=1, outFeatures=1) // Linear is a nn.Moduleval model = nn.Linear(inFeatures=12, outFeatures=1)val model = nn.Linear(inFeatures=12, outFeatures=8)val model = nn.Sequential( // Sequential is another nn.Module, a container
nn.Linear(12, 8),
nn.ReLU(), // ReLU is a non-linear activation function
nn.Linear(8, 2)
)val model = nn.Sequential( // Sequential is another nn.Module, a container
nn.Linear(12, 8),
nn.ReLU(), // ReLU is a non-linear activation function
nn.Linear(8, 8),
nn.ReLU(),
nn.Linear(8, 2)
)
import torch.nn.functional as F
import torch.nn
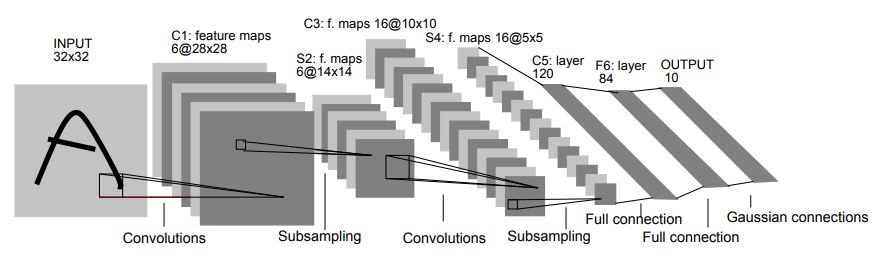
class LeNet[D <: BFloat16 | Float32: Default] extends nn.Module:
val conv1 = register(nn.Conv2d(1, 6, 5))
val conv2 = register(nn.Conv2d(6, 16, 5))
val fc1 = register(nn.Linear(16 * 4 * 4, 120))
val fc2 = register(nn.Linear(120, 84))
val fc3 = register(nn.Linear(84, 10))
def apply(i: Tensor[D]): Tensor[D] =
var x = F.maxPool2d(F.relu(conv1(i)), (2, 2))
x = F.maxPool2d(F.relu(conv2(x)), 2)
x = x.view(-1, 16 * 4 * 4)
x = F.relu(fc1(x))
x = F.relu(fc2(x))
x = fc3(x)
x
/** ResNet architecture implementations */
object resnet:
/** 3x3 convolution with padding */
def conv3x3[D <: BFloat16 | Float32 | Float64: Default](
inPlanes: Int,
outPlanes: Int,
stride: Int = 1,
groups: Int = 1,
dilation: Int = 1
): Conv2d[D] =
Conv2d[D](
inPlanes,
outPlanes,
kernelSize = 3,
stride = stride,
padding = dilation,
groups = groups,
bias = false,
dilation = dilation
)
/** 1x1 convolution */
def conv1x1[D <: FloatNN: Default](inPlanes: Int, outPlanes: Int, stride: Int = 1): Conv2d[D] =
Conv2d[D](inPlanes, outPlanes, kernelSize = 1, stride = stride, bias = false)
sealed abstract class BlockBuilder:
val expansion: Int
def apply[D <: BFloat16 | Float32 | Float64: Default](
inplanes: Int,
planes: Int,
stride: Int = 1,
downsample: Option[TensorModule[D]] = None,
groups: Int = 1,
baseWidth: Int = 64,
dilation: Int = 1,
normLayer: (Int => HasWeight[D] & TensorModule[D])
): TensorModule[D] = this match
case BasicBlock =>
new BasicBlock(inplanes, planes, stride, downsample, groups, baseWidth, dilation, normLayer)
case Bottleneck =>
new Bottleneck(inplanes, planes, stride, downsample, groups, baseWidth, dilation, normLayer)
object BasicBlock extends BlockBuilder:
override val expansion: Int = 1
object Bottleneck extends BlockBuilder:
override val expansion: Int = 4
class BasicBlock[D <: BFloat16 | Float32 | Float64: Default](
inplanes: Int,
planes: Int,
stride: Int = 1,
downsample: Option[TensorModule[D]] = None,
groups: Int = 1,
baseWidth: Int = 64,
dilation: Int = 1,
normLayer: => (Int => TensorModule[D])
) extends TensorModule[D] {
import BasicBlock.expansion
if groups != 1 || baseWidth != 64 then
throw new IllegalArgumentException("BasicBlock only supports groups=1 and baseWidth=64")
if dilation > 1 then throw new NotImplementedError("Dilation > 1 not supported in BasicBlock")
// Both conv1 and downsample layers downsample the input when stride != 1
val conv1 = register(conv3x3[D](inplanes, planes, stride))
val bn1 = register(normLayer(planes))
val relu = register(ReLU(inplace = true))
val conv2 = register(conv3x3[D](planes, planes))
val bn2 = register(normLayer(planes))
downsample.foreach(downsample => register(downsample)(using Name("downsample")))
def apply(x: Tensor[D]): Tensor[D] =
var identity = x
var out = conv1(x)
out = bn1(out)
out = relu(out)
out = conv2(out)
out = bn2(out)
downsample.foreach { downsample =>
identity = downsample(x)
}
out += identity
out = relu(out)
out
override def toString(): String = getClass().getSimpleName()
}
/** Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
* while original implementation places the stride at the first 1x1 convolution(self.conv1)
* according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
* This variant is also known as ResNet V1.5 and improves accuracy according to
* https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
*/
class Bottleneck[D <: BFloat16 | Float32 | Float64: Default](
inplanes: Int,
planes: Int,
stride: Int = 1,
downsample: Option[TensorModule[D]] = None,
groups: Int = 1,
baseWidth: Int = 64,
dilation: Int = 1,
normLayer: (Int => HasWeight[D] & TensorModule[D])
) extends TensorModule[D]:
import Bottleneck.expansion
val width = (planes * (baseWidth / 64.0)).toInt * groups
// Both self.conv2 and self.downsample layers downsample the input when stride != 1
val conv1 = register(conv1x1(inplanes, width))
val bn1 = register(normLayer(width))
val conv2 = register(conv3x3(width, width, stride, groups, dilation))
val bn2 = register(normLayer(width))
val conv3 = register(conv1x1(width, planes * expansion))
val bn3 = register(normLayer(planes * expansion))
val relu = register(ReLU(inplace = true))
downsample.foreach(downsample => register(downsample)(using Name("downsample")))
def apply(x: Tensor[D]): Tensor[D] =
var identity = x
var out = conv1(x)
out = bn1(out)
out = relu(out)
out = conv2(out)
out = bn2(out)
out = relu(out)
out = conv3(out)
out = bn3(out)
downsample.foreach { downsample =>
identity = downsample(x)
}
out += identity
out = relu(out)
out
override def toString(): String = getClass().getSimpleName()
class ResNet[D <: BFloat16 | Float32 | Float64](
block: BlockBuilder,
layers: Seq[Int],
numClasses: Int = 1000,
zeroInitResidual: Boolean = false,
groups: Int = 1,
widthPerGroup: Int = 64,
// each element in the tuple indicates if we should replace
// the 2x2 stride with a dilated convolution instead
replaceStrideWithDilation: (Boolean, Boolean, Boolean) = (false, false, false)
)(using Default[D])(
normLayer: (Int => HasWeight[D] & TensorModule[D]) =
(numFeatures => BatchNorm2d[D](numFeatures))
) extends Module {
var inplanes = 64
var dilation = 1
val baseWidth = widthPerGroup
val conv1 = register(Conv2d(3, inplanes, kernelSize = 7, stride = 2, padding = 3, bias = false))
val bn1 = register(normLayer(inplanes))
val relu = register(ReLU(inplace = true))
val maxpool = register(MaxPool2d(kernelSize = 3, stride = Some(2), padding = 1))
val layer1 = register(makeLayer(block, 64, layers(0)))
val layer2 = register(
makeLayer(block, 128, layers(1), stride = 2, dilate = replaceStrideWithDilation(0))
)
val layer3 = register(
makeLayer(block, 256, layers(2), stride = 2, dilate = replaceStrideWithDilation(1))
)
val layer4 = register(
makeLayer(block, 512, layers(3), stride = 2, dilate = replaceStrideWithDilation(2))
)
val avgpool = register(AdaptiveAvgPool2d((1, 1)))
val fc = register(Linear(512 * block.expansion, numClasses))
for (m <- modules)
m match
case m: Conv2d[?] =>
nn.init.kaimingNormal_(m.weight, mode = Mode.FanOut, nonlinearity = NonLinearity.ReLU)
case m: BatchNorm2d[?] =>
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
case m: nn.GroupNorm[?] =>
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
case _ =>
// Zero-initialize the last BN in each residual branch,
// so that the residual branch starts with zeros, and each residual block behaves like an identity.
// This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zeroInitResidual then
for (m <- modules)
m match
case m: Bottleneck[?] if m.bn3.weight.dtype != DType.undefined =>
nn.init.constant_(m.bn3.weight, 0)
case m: Bottleneck[?] if m.bn2.weight.dtype != DType.undefined =>
nn.init.constant_(m.bn2.weight, 0)
private def makeLayer(
block: BlockBuilder,
planes: Int,
blocks: Int,
stride: Int = 1,
dilate: Boolean = false
): Sequential[D] = {
var downsample: Option[TensorModule[D]] = None
val previous_dilation = this.dilation
var _stride: Int = stride
if dilate then
this.dilation *= stride
_stride = 1
if _stride != 1 || inplanes != planes * block.expansion then
downsample = Some(
Sequential(
conv1x1(inplanes, planes * block.expansion, _stride),
normLayer(planes * block.expansion)
)
)
var layers = Vector[TensorModule[D]]()
layers = layers :+ block(
this.inplanes,
planes,
_stride,
downsample,
this.groups,
this.baseWidth,
previous_dilation,
normLayer
)
inplanes = planes * block.expansion
for (_ <- 1 until blocks)
layers = layers :+
block(
this.inplanes,
planes,
groups = this.groups,
baseWidth = this.baseWidth,
dilation = this.dilation,
normLayer = normLayer
)
Sequential(layers*)
}
private inline def forwardImpl(_x: Tensor[D]): Tensor[D] =
var x = conv1(_x)
x = bn1(x)
x = relu(x)
x = maxpool(x)
x = layer1(x)
x = layer2(x)
x = layer3(x)
x = layer4(x)
x = avgpool(x)
x = x.flatten(1)
fc(x)
def apply(x: Tensor[D]): Tensor[D] = forwardImpl(x)
}
private val weightsBaseUrl =
"https://github.com/sbrunk/storch/releases/download/pretrained-weights/"
case class Weights(
url: String,
transforms: Presets.ImageClassification
)
abstract class ResNetFactory:
def apply[D <: BFloat16 | Float32 | Float64: Default](numClasses: Int = 1000): ResNet[D]
val DEFAULT: Weights
/** ResNet-18 from [Deep Residual Learning for Image
* Recognition](https://arxiv.org/pdf/1512.03385.pdf).
*/
object ResNet18 extends ResNetFactory:
def apply[D <: BFloat16 | Float32 | Float64: Default](numClasses: Int = 1000) =
ResNet[D](BasicBlock, Seq(2, 2, 2, 2), numClasses)()
val IMAGENET1K_V1 = Weights(
url = weightsBaseUrl + "resnet18-f37072fd.pth",
Presets.ImageClassification(cropSize = 224)
)
val DEFAULT = IMAGENET1K_V1
/** ResNet-34 from [Deep Residual Learning for Image
* Recognition](https://arxiv.org/pdf/1512.03385.pdf).
*/
object ResNet34 extends ResNetFactory:
def apply[D <: BFloat16 | Float32 | Float64: Default](numClasses: Int = 1000) =
ResNet[D](BasicBlock, Seq(3, 4, 6, 3), numClasses = numClasses)()
val IMAGENET1K_V1 = Weights(
url = weightsBaseUrl + "resnet34-b627a593.pth",
transforms = Presets.ImageClassification(cropSize = 224)
)
val DEFAULT = IMAGENET1K_V1
/** ResNet-50 from [Deep Residual Learning for Image
* Recognition](https://arxiv.org/pdf/1512.03385.pdf)
*/
object ResNet50 extends ResNetFactory:
def apply[D <: BFloat16 | Float32 | Float64: Default](numClasses: Int = 1000) =
ResNet(Bottleneck, Seq(3, 4, 6, 3), numClasses = numClasses)()
val IMAGENET1K_V1 = Weights(
url = weightsBaseUrl + "resnet50-0676ba61.pth",
transforms = Presets.ImageClassification(cropSize = 224)
)
val IMAGENET1K_V2 = Weights(
url = weightsBaseUrl + "resnet50-11ad3fa6.pth",
transforms = Presets.ImageClassification(cropSize = 224, resizeSize = 232)
)
val DEFAULT = IMAGENET1K_V2
/** ResNet-101 from [Deep Residual Learning for Image
* Recognition](https://arxiv.org/pdf/1512.03385.pdf)
*/
object ResNet101 extends ResNetFactory:
def apply[D <: BFloat16 | Float32 | Float64: Default](numClasses: Int = 1000) =
ResNet(Bottleneck, Seq(3, 4, 23, 3), numClasses = numClasses)()
val IMAGENET1K_V1 = Weights(
url = weightsBaseUrl + "resnet101-63fe2227.pth",
transforms = Presets.ImageClassification(cropSize = 224)
)
val IMAGENET1K_V2 = Weights(
url = weightsBaseUrl + "resnet101-cd907fc2.pth",
transforms = Presets.ImageClassification(cropSize = 224, resizeSize = 232)
)
val DEFAULT = IMAGENET1K_V2
/** ResNet-152 from [Deep Residual Learning for Image
* Recognition](https://arxiv.org/pdf/1512.03385.pdf)
*/
object ResNet152 extends ResNetFactory:
def apply[D <: BFloat16 | Float32 | Float64: Default](numClasses: Int = 1000) =
ResNet(Bottleneck, Seq(3, 8, 36, 3), numClasses = numClasses)()
val IMAGENET1K_V1 = Weights(
url = weightsBaseUrl + "resnet152-394f9c45.pth",
transforms = Presets.ImageClassification(cropSize = 224)
)
val IMAGENET1K_V2 = Weights(
url = weightsBaseUrl + "resnet152-f82ba261.pth",
transforms = Presets.ImageClassification(cropSize = 224, resizeSize = 232)
)
val DEFAULT = IMAGENET1K_V2
enum ResNetVariant(val factory: ResNetFactory):
case ResNet18 extends ResNetVariant(resnet.this.ResNet18)
case ResNet34 extends ResNetVariant(resnet.this.ResNet34)
case ResNet50 extends ResNetVariant(resnet.this.ResNet50)
case ResNet101 extends ResNetVariant(resnet.this.ResNet101)
case ResNet152 extends ResNetVariant(resnet.this.ResNet152)